こんちゃ(´・ω・)ノ
Solr4.0とTomcat7の組み合わせでの
構築手順を記載するよ!
※そのうちSolr4.0+Jetty(同梱)の手順も書いておこうと思う。
<%SOLR_INST_HOME%>:Solrのインストーラホームディレクトリ
<%SOLR_HOME%>:Solrのホームディレクトリ
<%TOMCAT_HOME%>:TOMCATのホームディレクトリ
【環境】
・Apache Tomcat 7.0.32
・Apache Solr 4.0
・JDK 1.6.0_24
【事前準備】
・Tomcat7を構築済みであること。
Tomcat7のインストール方法はこちらを参照。
http://itdata.blog.shinobi.jp/Entry/84/私は最初すでに入っていたtomcat7.0.12でやったが
「SetCharacterEncodingFilter」関連の設定で上手くいかず、
tomcat7.0.32でやったら上手くいった。
そのため以下に記載する手順は「SetCharacterEncodingFilter」が
入ってるtomcatでの手順となっています。
・Javaの設定が完了していること。
JDKのインストール
環境変数のPATHおよびJAVA_HOMEの設定
・Solr4.0のダウンロード
http://www.apache.org/dyn/closer.cgi/lucene/solr/4.0.0「apache-solr-4.0.0.zip」をダウンロードする。
【インストール】
1.解凍
「apache-solr-4.0.0.zip」を解凍する。
解凍してできたディレクトリを<%SOLR_INST_HOME%>とする。
※Solrのディレクトリ構成はこちらを参照
http://itdata.blog.shinobi.jp/Entry/85/2.solrホームディレクトリの配備
「<%SOLR_INST_HOME%>/example/solr」ディレクトリを
「<%TOMCAT_HOME%>」配下に配置する。
配置したディレクトリを<%SOLR_HOME%>とする。
※<%SOLR_HOME%>自体は他の場所で問題はない。
また、「<%SOLR_INST_HOME%>/contrib」と
「<%TOMCAT_HOME%>/dist」ディレクトリを
<%SOLR_HOME%>の配下に配置する。
3. WARファイルの配備
「<%SOLR_INST_HOME%>/example/webapps/solr.war」を
「<%TOMCAT_HOME%>/webapps」に配置して解凍する。
※上手く解凍できない場合は、solr.warだけを置いて、TOMCATを起動すれば、
自動でデプロイ(解凍)してくれる。
4. tomcat7のsolr用設定
・server.xmlの編集
「<%TOMCAT_HOME%>/conf/server.xml」を編集
「useBodyEncodingForURI」を追加する。
----------------------------------------------------------------------------
<Connector port="8090" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" useBodyEncodingForURI="true"/>
----------------------------------------------------------------------------
・solrのweb.xmlの編集
「<%TOMCAT_HOME%>/webapps/solr/WEB-INF/web.xml」を編集
SolrRequestFilterの手前に追加
----------------------------------------------------------------------------
<filter>
<filter-name>SetCharacterEncoding</filter-name>
<filter-class>org.apache.catalina.filters.SetCharacterEncodingFilter</filter-class>
<init-param>
<param-name>encoding</param-name>
<param-value>UTF-8</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>SetCharacterEncoding</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
----------------------------------------------------------------------------
・solr.xmlの追加
「<%TOMCAT_HOME%>/conf/Catalina/localhost」にsolr.xmlを作成する。
※ディレクトリが存在しない場合は作成する。
----------------------------------------------------------------------------
<?xml version="1.0" encoding="utf-8"?>
<Context docBase="<%TOMCAT_HOME%>/webapps/solr" debug="0" crossContext="true">
<Environment name="solr/home" type="java.lang.String" value="<%SOLR_HOME%>" override="true"/>
</Context>
----------------------------------------------------------------------------
5. solrの設定
・solrconfig.xmlの編集
「<%SOLR_HOME%>/collection1/conf/solrconfig.xml」を編集する。
インデックス用のデータディレクトリと各種ライブラリへのパスを設定する。
----------------------------------------------------------------------------
(省略)
<lib dir="<%SOLR_HOME%>/contrib/extraction/lib" regex=".*\.jar" />
<lib dir="<%SOLR_HOME%>/dist/" regex="apache-solr-cell-\d.*\.jar" />
<lib dir="<%SOLR_HOME%>/contrib/clustering/lib/" regex=".*\.jar" />
<lib dir="<%SOLR_HOME%>/dist/" regex="apache-solr-clustering-\d.*\.jar" />
<lib dir="<%SOLR_HOME%>/contrib/langid/lib/" regex=".*\.jar" />
<lib dir="<%SOLR_HOME%>/dist/" regex="apache-solr-langid-\d.*\.jar" />
<lib dir="<%SOLR_HOME%>/contrib/velocity/lib" regex=".*\.jar" />
<lib dir="<%SOLR_HOME%>/dist/" regex="apache-solr-velocity-\d.*\.jar" />
(省略)
<dataDir>${solr.data.dir:<%SOLR_HOME%>/collection1/data}</dataDir>
(省略)
<updateLog>
<str name="dir">${solr.data.dir:<%SOLR_HOME%>/collection1/data}</str>
</updateLog>
----------------------------------------------------------------------------
6.TOMCAT起動
「<%TOMCAT_HOME%>/bin/startup.bat」を実行する。
※linuxの場合はstartup.sh
【操作】
1.管理画面ログイン
以下のURLで管理画面を起動する。
http://localhost:8080/solr/※IE8だとJavaScriptエラーで表示されませんでした。
※GoogleChrome、FireFoxだと表示されました。
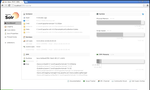
2.Analyse
左メニューから[colection1]-[Analysis]を選択。
Field Value(INDEX)に「庭には二羽ニワトリがいる」と入力
Analyse Fieldname/FieldTypeを「text_ja」に選択
[Analyse Values]ボタンを押下する。
※この時文字化けされずに表示されればOK
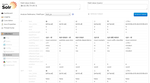
3.Query
①現状確認
左メニューから[colection1]-[Query]を選択。
qの部分に「solr」を入力。
indentにチェックを入れる。
[Execute Query]ボタンを押下する。
クエリー: http://localhost:8080/solr/collection1/select?q=solr&wt=xml
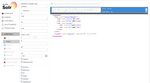
文書が登録されている場合のレスポンスはこちら
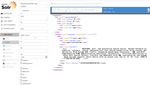
※GoogleChromeでXML構造を参照するには右クリックから「要素を検証」で一応確認できる。最初からXML構造を表示するにはプラグイン(XML Tree)を入れる。
②文書登録
標準でついているサンプルの
<%SOLR_INST_HOME%>/example/exampledocs/post.jarを使用し、
文書をSolrに登録する。
コマンド:「java -jar post.jar solr.xml」
※1 デフォルトでは「http://localhost:8983/solr/update」にリクエストが送信されるため、
「-Durl」オプションでURLを指定して実行する。
(例)
コマンド:「java -jar -Durl=http://localhost:8080/solr/update post.jar solr.xml」
※2 文書登録検索削除のサンプル作ってみた!( ゚Д゚ )
solrClient.zip検索、登録、削除ができるよ!
パスワード:「bkyo20121121」
■まとめ
意外と手間取った。
というのもやはり手順を確立し、書きながらだと結構時間かかるね!
今後Solrではjavaのサンプルをいくつか書いて上げていこうと思うので、
そちらもよろしくです。
 [8回]
[8回]